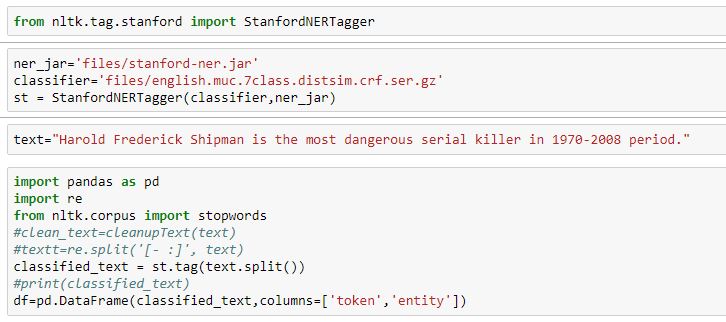
Bayesien classifier

The simplest solutions are the most powerful, and Naive Bayes is a good example. Despite the great advances in machine learning in recent years, it has proven to be not only simple but also fast, accurate and reliable. It has been successfully used with several fins, but it works very well with natural language processing problems.
Naive Bayes is a family of probabilistic algorithms that take advantage of probability theory and Bayes' theorem to predict the category of a sample. They are probabilistic, which means they calculate the probability of each category for a given sample, and then output the category with the highest probability. The way they obtain these probabilities is by using the Bayes theorem, which describes the probability of a feature, depending on prior knowledge of the conditions that could be related to this feature
We will work with an algorithm called Multinomial Naive Bayes. So at the end we will know how this method works, but also why it works. Then we will be able to do some advanced techniques that can make Naive Bayes competitive with more complex machine learning algorithms, such as SVM and neural networks..
example:
| Text | Category |
| “Barack Obama is the president of the U.S” | Politics |
| “Football is my favorite game” | Sports |
| “federer wimbledon is the best Tennis Player ” | Sports |
| “i need to contact my bank to get a loan” | Financial world |
| “Trump is the most stupid president” | Politics |
Now, which category does the sentence "Barack Obama is the president of the U.S" belong to?
Because Naive Bayes classifier is probabilistic, we want to calculate the probability that the sentence "Barack Obama is the president of the U.S" is Politics, and the probability that it is in other categories. Then we take the largest one. Mathematically, what we want is P (Politics | Barack Obama is the president of the U.S) which means the probability that the category of a sentence is Politics given that the sentence is "Barack Obama is the president of the U.S".
Great, but how do we calculate those probabilities? Let's see!!
Feature-Extraction
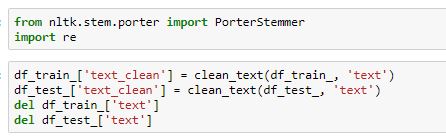
The first thing we need to do when creating a machine learning model is to decide what to use as features. It is well known that reducing the number of input variables through dimensionality reduction techniques such as feature extraction is desirable. Features are expected to contain the relevant information from the input data, so that the desired task can be performed by using this reduced representation instead of the complete initial data. To better understand this approach, let's say that we are training a model for "health and medicine" category. A person's height or weight is important for us but the person name, eye color or skin color is not important for the model, so we exclude those unuseful features.
But, in this case, we don’t even have numeric features. We just have text. We need to somehow convert this text into numbers that we can do calculations on which is known by words to frequencies.
From Words to Frequencies
we ignore word order and sentence construction, treating every document as a set of the words it contains. Our features will be the counts of each of these words. Even though it may seem too simplistic an approach, it works surprisingly well. We call vectorization the general process of turning a collection of text documents into numerical feature vectors. This specific strategy (tokenization, counting and normalization) is called the Bag of Words or “Bag of n-grams” representation. Documents are described by word occurrences while completely ignoring the relative position information of the words in the document.
Bayes Theorem
Now we need to transform the probability we want to calculate into something that can be calculated using word frequencies. That's why we will use some basic properties of probability and bayes theorem. To work with Bayes theorem, you need to know about conditional probability.
Conditional probability can be thought of as looking at the probability of one event occurring with some relationship to one or more other events. For example:
- Event A is that it is snowing outside, and it has a 0.3 (30%) chance of snowing today.
- Event B is that you will need to go outside, and that has a probability of 0.5 (50%).
A conditional probability would look at these two events in relationship with one another, such as the probability that it is both snowing and you will need to go outside.
The formula for conditional probability is:
P(B|A) = P(A and B) / P(A)
which can also be rewritten as:
P(B|A) = P(A∩B) / P(A)
or P(A∩B)=P(A|B) .P(B)
P(B|A) = P(A|B) .P(B) / P(A)
In our case, using the conditional probability theorem, we have P(Politics | Barack Obama is the president of the U.S)=P(Barack Obama is the president of the U.S | Politics ) . P(Politics) / P(Barack Obama is the president of the U.S)
Since for our classifier we’re just trying to find out which category has a bigger probability, we can discard the divisor for all probability calculations P(Politics | Barack Obama is the president of the U.S), P(Sports | Barack Obama is the president of the U.S), P(Financial world | Barack Obama is the president of the U.S) .....
We will just count how many times the sentence “Barack Obama is the president of the U.S” appears in the Politics category, divide it by the total, and obtain P(Barack Obama is the president of the U.S | Politics).
But this way, We could have a problem: “Barack Obama is the president of the U.S” could not appear in our training set, so the probability will be zero. Unless every sentence that we want to classify appears in our training set, the model would not be useful.
Naive Bayes
Here we can talk about Naive Bayes. Being naive will help us to get a better model to classify our sentence in the correct category. We suppose that every word in a sentence is independent from the others. That means that we will no longer look for the probability of the entire sentence, but we yill search the probability of individual words.
So "Barack Obama is the president of the U.S" is the same as "the president of the U.S is Barack Obama " as well as "Obama Barack is the president of the U.S" ..
Therefore, P(Barack Obama is the president of the U.S)= P(Barack)*P(Obama)*P(is)*P(the)*P(president)*P(of)*P(the)*P(U.S)
This hypothesis is very strong and super useful. This is why this model works well with small data set or data that can be mislabeled. The next step is exactly what we had before:
P(Barack Obama is the president of the U.S | Politics )= P(Barack | Politics)*P(Obama | Politics)*P( is | Politics )*P( the | Politics )*P( president | Politics )*P( of | Politics )*P( the | Politics )*P( U.S | Politics )
Now all of these individual words show up several times in our training set, and we can calculate them!
The final step is just to calculate every probability (for each category) and see which one turns out to be larger.
We will just count how many times the sentence “Barack Obama is the president of the U.S” appears in the Politics category, divide it by the total, and obtain P(Barack Obama is the president of the U.S | Politics).
But this way, We could have a problem: “Barack Obama is the president of the U.S” could not appear in our training set, so the probability will be zero. Unless every sentence that we want to classify appears in our training set, the model would not be useful.
Naive Bayes
Here we can talk about Naive Bayes. Being naive will help us to get a better model to classify our sentence in the correct category. We suppose that every word in a sentence is independent from the others. That means that we will no longer look for the probability of the entire sentence, but we yill search the probability of individual words.
So "Barack Obama is the president of the U.S" is the same as "the president of the U.S is Barack Obama " as well as "Obama Barack is the president of the U.S" ..
Therefore, P(Barack Obama is the president of the U.S)= P(Barack)*P(Obama)*P(is)*P(the)*P(president)*P(of)*P(the)*P(U.S)
This hypothesis is very strong and super useful. This is why this model works well with small data set or data that can be mislabeled. The next step is exactly what we had before:
P(Barack Obama is the president of the U.S | Politics )= P(Barack | Politics)*P(Obama | Politics)*P( is | Politics )*P( the | Politics )*P( president | Politics )*P( of | Politics )*P( the | Politics )*P( U.S | Politics )
Now all of these individual words show up several times in our training set, and we can calculate them!
The final step is just to calculate every probability (for each category) and see which one turns out to be larger.
















































{kind=link}