NLP Processing using NLTK Stanford core nlp
Can computers understand humans?
 NLP is a very important branch of Machine Learning and therefore of artificial intelligence. The NLP is the ability of a program to understand human language.
NLP is a very important branch of Machine Learning and therefore of artificial intelligence. The NLP is the ability of a program to understand human language.Let's take a few practical examples that are used every day to better understand:
- Spam: all mailboxes use an anti-spam filter and it works with Bayesian filtering in reference to the Bayes theorem which is a statistical technique for detecting spam. These filters will "understand" the text and find out if there are correlations of words that indicate spam.
- Google Translation: you probably have all used this system and their technology uses many algorithms including NLP. Here, the challenge is not to translate the word, but to keep the meaning of a sentence in another language.
- The Siri software created by Apple or Google Assistant uses NLP to translate transcribed text into analyzed text in order to give you an answer adapted to your request.
Today we will make some NLP processing, using NLTK Stanford core nlp.
We need for that jupyter notebook and python3.
You can find the full notebook HERE




 Coreference resolution is the task of finding all expressions that refer to the same entity in a text. It is an important step for a lot of higher level NLP tasks that involve natural language understanding such as document summarization, question answering, and information extraction.
Coreference resolution is the task of finding all expressions that refer to the same entity in a text. It is an important step for a lot of higher level NLP tasks that involve natural language understanding such as document summarization, question answering, and information extraction.

You can find the full notebook HERE
POS-Tag
The process of classifying words into their parts of speech and labeling them accordingly is known as part-of-speech tagging, POS-tagging, or simply tagging. Parts of speech are also known as word classes or lexical categories. The collection of tags used for a particular task is known as a tagset.
Parsing
A natural language parser is a program that works out the grammatical structure of sentences, for instance, which groups of words go together (as "phrases") and which words are the subject or object of a verb.
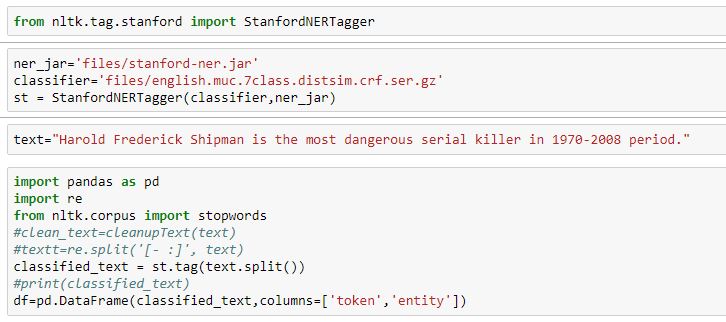
NER
Named Entity Recognition (NER) labels sequences of words in a text which are the names of things, such as person and company names, or gene and protein names
Here are the results
We will try to remove the other things.
Coref-Resolution
 Coreference resolution is the task of finding all expressions that refer to the same entity in a text. It is an important step for a lot of higher level NLP tasks that involve natural language understanding such as document summarization, question answering, and information extraction.
Coreference resolution is the task of finding all expressions that refer to the same entity in a text. It is an important step for a lot of higher level NLP tasks that involve natural language understanding such as document summarization, question answering, and information extraction.
I will use core nlp server for coreference resolution
You can run the server using this command:
java -mx4g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer
You can use the server for parsing , part of speech tagging or any other tool of stanford core nlp.



best post.
ReplyDeletepython training