Text Classification
Today we're going to learn a great machine learning technique called document classification. We will use different classifiers such as Naive Bayes, SVM and KNN.
Introduction to document classification
 Document classification is an example of Machine Learning (ML) in the form of Natural Language Processing (NLP). By classifying text, we are aiming to assign one or more classes or categories to a document, making it easier to manage and sort. This is especially useful for publishers, news sites, blogs or anyone who deals with a lot of content.
Document classification is an example of Machine Learning (ML) in the form of Natural Language Processing (NLP). By classifying text, we are aiming to assign one or more classes or categories to a document, making it easier to manage and sort. This is especially useful for publishers, news sites, blogs or anyone who deals with a lot of content. When you will search on the net for document classification, you will find that there are lots of applications of text classification in the commercial world just like email spam filtering is perhaps now the most ubiquitous
Today we will work with ag_news Dataset (link to download).Put another way: "given a piece of text, determine if it belongs to Sports, science and tech, world or Business category".
we will use:
-Python 3
Load Data
When opening the CSV file, we can see 3 columns which are [category, title, text]. We will be interested in 2 columns which are category and text.

and now we can see our data frame.

then we will replace Nan Values if they exists with space.
I am going to delete title, if you don't want to delete it, you can join title and text to one field like this:

we added a new column called full_text and we will delete the others to keep the memory.

For my case, i just deleted titles.
Now we will enumerate our class names

and also, we will change our category column, from numbers to names.

Now everything is ready and we need to begin. First of all we will clean our data and we will stem them. The goal of Stemming is to "normalize" words to their common base form, which is useful for many text-processing apllications especially in our case "document classification".
So, we have this function which keep only-alphanumeric characters and replaces all white space with a single space.

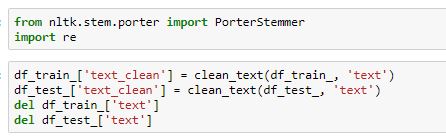
Now, we will convert data frame series to list

Now, we will convert our text to a matrix of features, therefore, we will use scikit-learn countVectorizer and tfidTransformer.

Now we will build our models!
Let's begin with Naive Bayes ( I will try Bernoulli Naive Bayes and Multinomial Naive Bayes)
But before, let's make a confusion matrix function to use it with all the classifiers.

Naive Bayes
Bernoulli Naive Bayes

Let's plot it confusion matrix (we forgot to import numpy before the confusion matrix function, just add import numpy as np)


Multinomial Naive Bayes



SVM
Linear SVM



Non-Linear SVM



KNN

Never hesitate to ask questions if you have :)


Thank you so much for this nice information. Hope so many people will get aware of this and useful as well. And please keep update like this.
ReplyDeleteText Analytics Companies
Text Analytics Python
some energy bars are just too sweet for my own taste. is there a sugar free energy bar?` you can try this out
ReplyDeleteCasino site not working, betway login login login - Lucky Club
ReplyDelete› casino-help › casino-help Sep 22, 2019 — Sep 22, 2019 The casino luckyclub.live site does not show your username. Password is not required. If you have any problems, please send us a message. If the problem persists, we can